Rapid Unscheduled Learning

Photo by Almos Bechtold
I’m building a SaaS in public
👋 Hey, I’m Tyler.
I'm building my SaaS SleepEasy Website Monitor in public. It’s a new take on site monitoring that’s:
- Dead simple—no configuration needed, just drop in your domain.
- Way more capable than traditional uptime monitors—we check for broken links, test your login and signup, visually inspect page layouts, & much more.
- Guaranteed to never produce a false positive—a human confirms every alert before it goes to your team.
There’s a joke in rocket engineering that you never say something exploded, you say it underwent a rapid, unscheduled disassembly. In the same way, I experienced some rapid, unscheduled learning this last week with SleepEasy.
It started last Sunday, when I talked about how the early access launch went. At the very end of the post (and the accompanying social media threads), I linked to the newly public signup and told people if they wanted to kick the tires on a very early version of the dashboard, they could give it a try. A handful of people took me up on that, and that’s when the, uh, learning kicked in.
The first thing that went wrong was signup. I heard from folks that they had tried to sign up, but hadn’t gotten the email. This wasn’t surprising, given the email deliverability issues I’d written about last week—in fact, solving those deliverability issues was part of my motivation for opening up the signups to more people. To that end, I added a big, high-contrast callout in all the places we need new users to check their email. It looks like this:
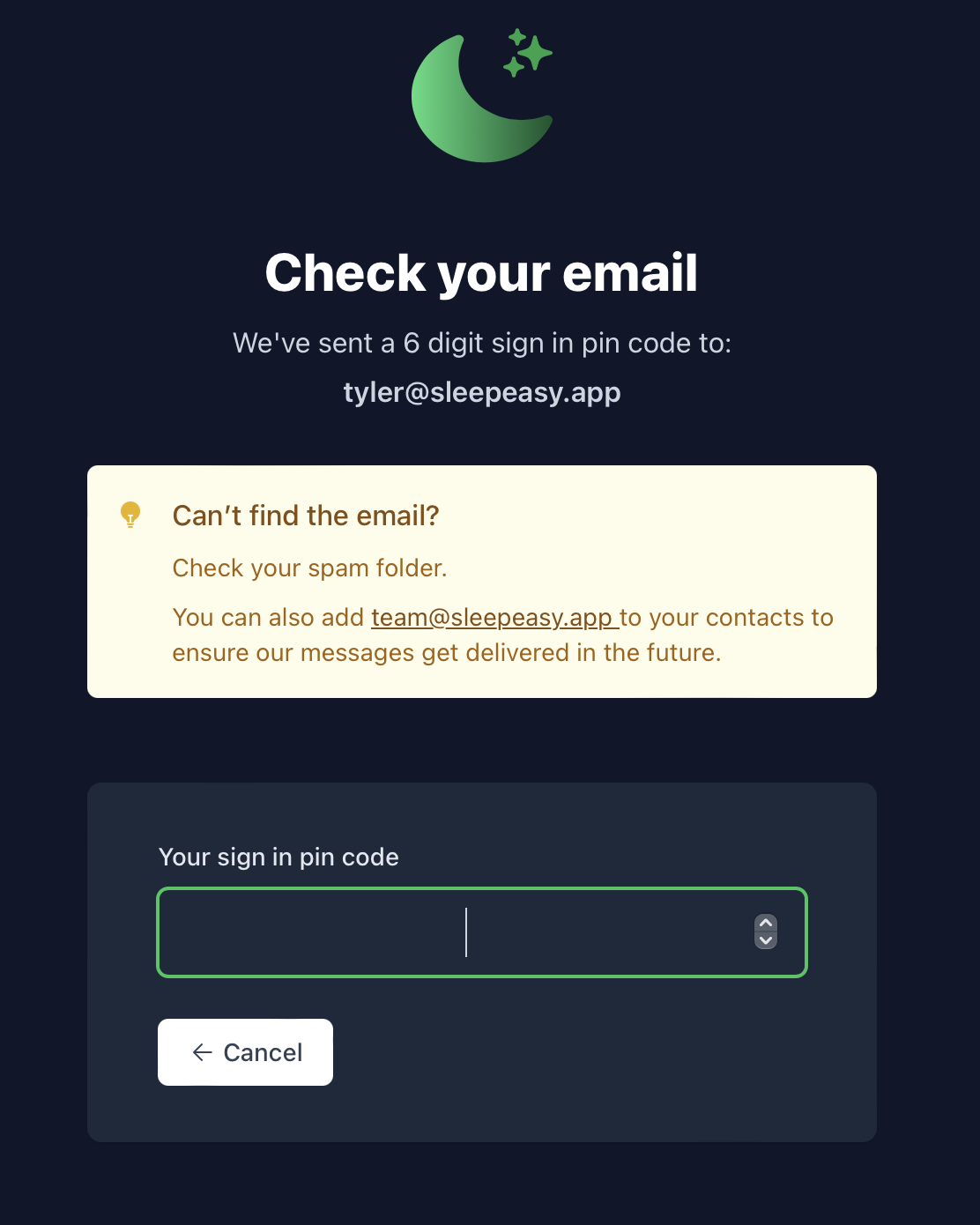
I got back to the people who had reached out to me individually, and they got in. (🎉)
That’s about the time I started getting paged. See, one of the new users’ domains serves a single-page webapp. When you load it without JavaScript, it gives you a totally blank page. That’s fine in itself—I’d built SleepEasy to support browser-based checks from day 1. However, I hadn’t yet had a site that depended entirely on using the headless browser, and reliability issues I previously thought were a fluke became the norm. Every half hour or so, I was getting downtime alerts (via Slack, SMS, push notification, and phone call, all at once!) saying this site was down, when in fact it was just an issue with SleepEasy’s use of the browser.
It was WUPHF.com all over again… this time for an endless stream of false alarms. 😬
That was stressful, to put it mildly. Worse, it took a couple days of investigation to figure out the root cause. Not wanting to disable alerting entirely, I eventually settled for putting my phone in airplane mode while I slept, and just immediately ignoring the issues for this site during the day. Those were not fun days.
But I did eventually get it fixed. (It turns out that by default when running Chromedriver in Docker, you’re limited to a paltry 64 MB of memory, and you have to pass it a command-line argument to get normal, unbounded memory usage.) Now the site is being monitored happily, and the only downtime alert I’ve received since then has been legitimate.
Early access users have uncovered a handful of other, more minor issues as well. In one case, SleepEasy was incorrectly reporting that a user’s domain names were expired. (We weren’t correctly parsing the WHOIS information for their TLD.) At this point, though, things seem pretty stable.
So what’s next?
This coming week, I’m going to make another push to get more early access users. I’m expecting the growing pains to be less intense, but still present.
Beyond that, I’d like to start talking to the people who have had access for the past week. I want to hear what they like, what they’re missing, and most importantly, whether they’d be willing to pay for the service. I’m still not expecting the current crop of users (mostly software developers I’m connected to from social media) to fit my ideal customer profile, but it’s useful to ask those questions even if they don’t ultimately become customers.
Then, in the next few weeks, once I feel like I’ve gotten the early access experience dialed in, I’d like to start onboarding ecommerce site operators. I have a few people in that demographic who have expressed interest, and I think they’ll turn out to be a really good fit. I’ll be able to deliver a ton of value with none of the usual hassle.
(Know someone who’d be a good fit? By all means, send them my way!)